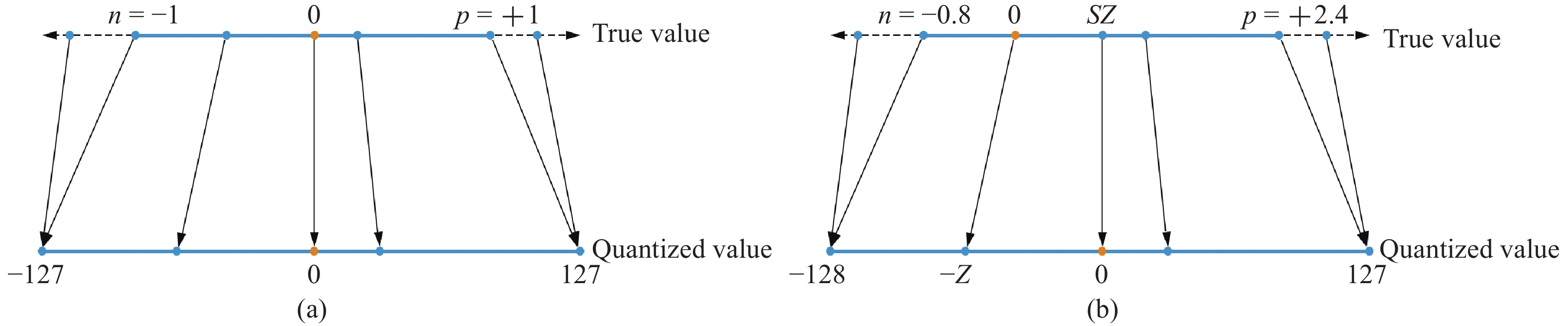
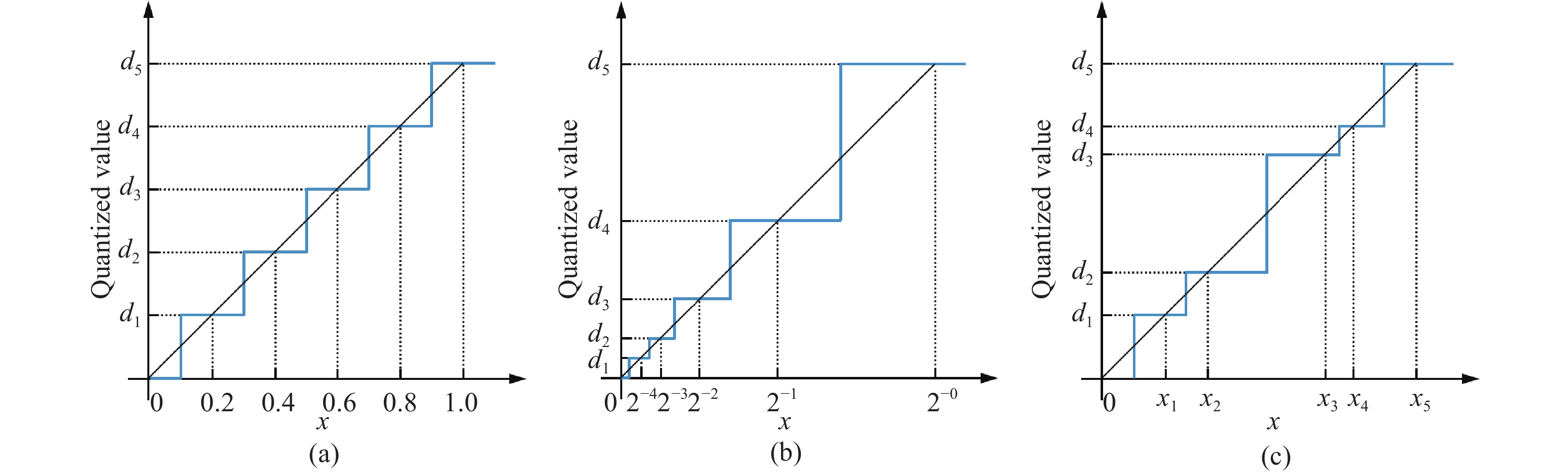
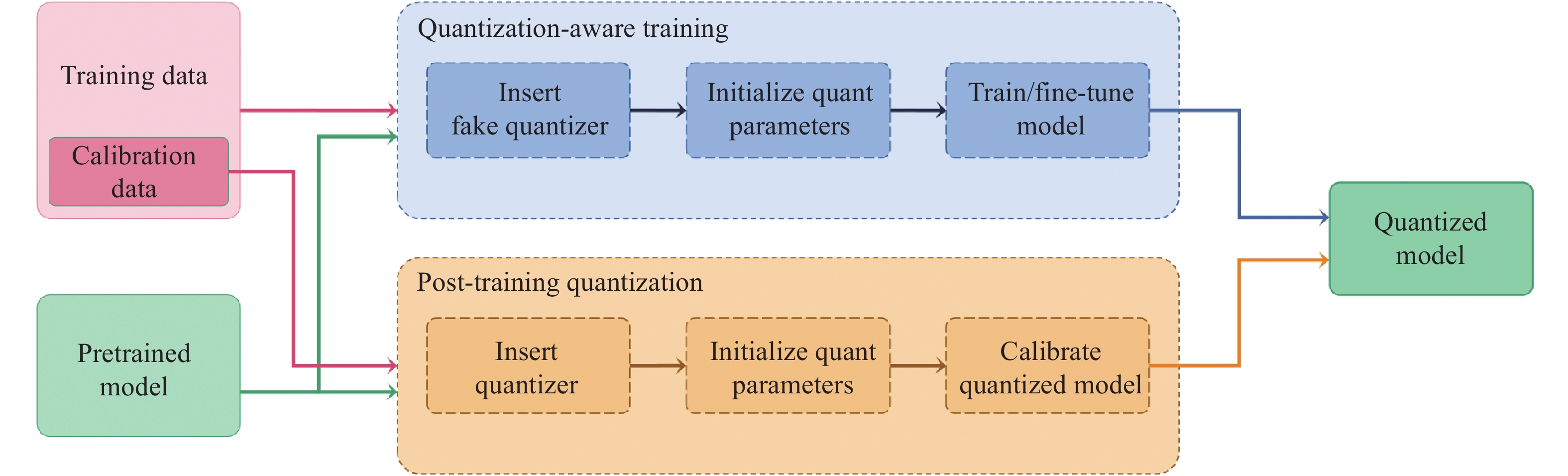
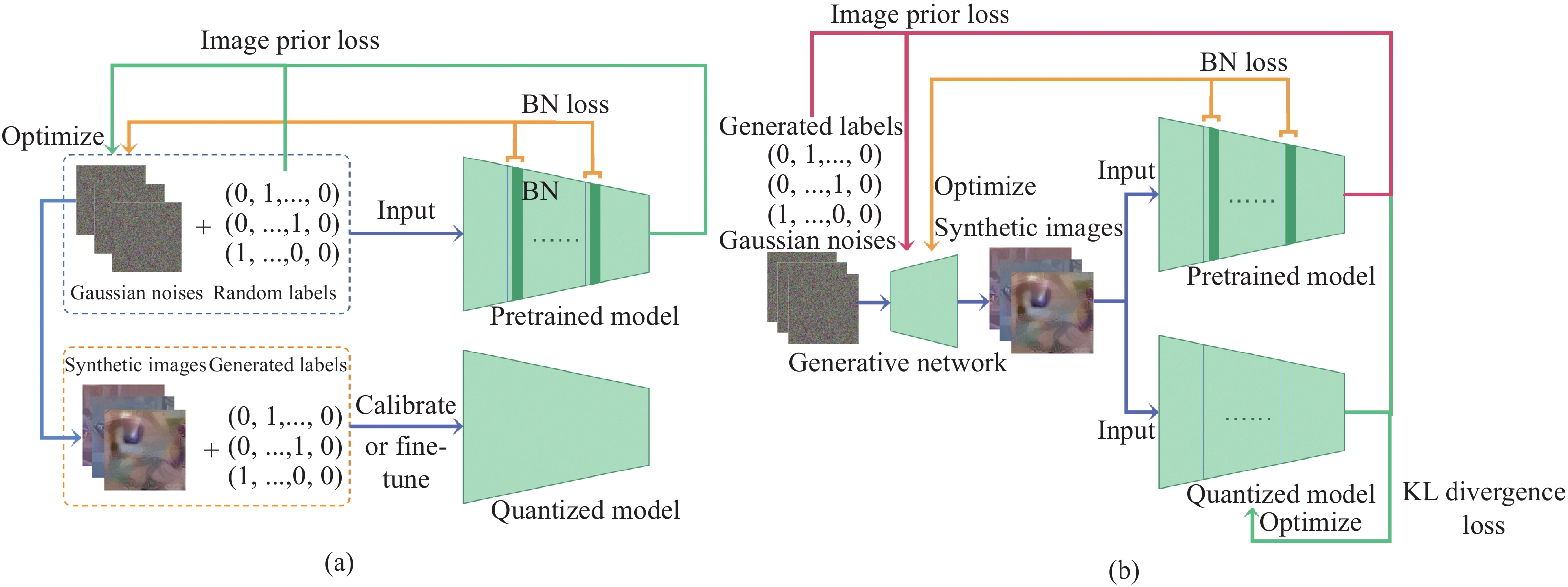
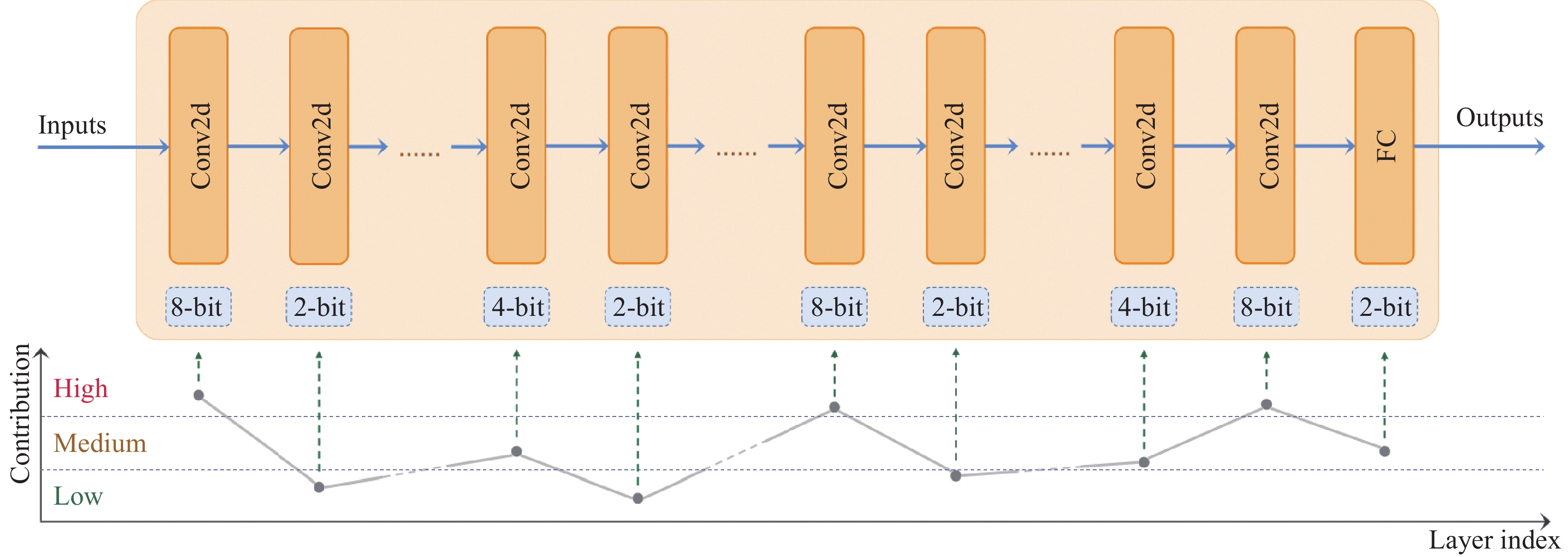
| Citation: | YANG Chun, ZHANG Ruiyao, HUANG Long, TI Shutong, LIN Jinhui, DONG Zhiwei, CHEN Songlu, LIU Yan, YIN Xucheng. A survey of quantization methods for deep neural networks[J]. Chinese Journal of Engineering, 2023, 45(10): 1613-1629. doi: 10.13374/j.issn2095-9389.2022.12.27.004

|
| [1] |
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks // Advances in Neural Information Processing Systems. Lake Tahoe, 2012: 1106
|
| [2] |
Russakovsky O, Deng J, Su H, et al. ImageNet large scale visual recognition challenge // Int J Comput Vis, 2015, 115(3): 211
|
| [3] |
Yu J H, Wang Z, Vasudevan V, et al. CoCa: Contrastive captioners are image-text foundation models [J/OL]. arXiv preprint (2022-06-15) [2022-12-27]. https://arxiv.org/abs/2205.01917
|
| [4] |
Deng J, Dong W, Socher R, et al. Imagenet: A large-scale hierarchical image database // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Miami, 2009: 248
|
| [5] |
Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale [J/OL]. arXiv preprint (2020-10-22) [2022-12-27]. https://arxiv.org/abs/2010.11929
|
| [6] |
Krizhevsky A. Learning multiple layers of features from tiny images [J/OL]. Sciencepaper Online (2009-04-08) [2022-12-27]. http://www.cs.utoronto.ca/~kriz/learning-features-2009-TR.pdf
|
| [7] |
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need // Advances in Neural Information Processing Systems. Long Beach, 2017: 5998
|
| [8] |
Brown T B, Mann B, Ryder N, et al. Language models are few-shot learners // Advances in Neural Information Processing Systems. Vancouver, 2020: 1877
|
| [9] |
He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, 2016: 770
|
| [10] |
Dong X, Chen S, Pan S. Learning to prune deep neural networks via layer-wise optimal brain surgeon // Advances in Neural Information Processing Systems. Long Beach, 2017: 4857
|
| [11] |
Liu Z, Li J, Shen Z, et al. Learning efficient convolutional networks through network slimming // Proceedings of the IEEE International Conference on Computer Vision. Venice, 2017: 2755
|
| [12] |
He Y H, Lin J, Liu Z J, et al. Amc: Automl for model compression and acceleration on mobile devices // Proceedings of the European Conference on Computer Vision. Munich, 2018: 815
|
| [13] |
Romero A, Ballas N, Kahou S E, et al. Fitnets: Hints for thin deep nets [J/OL]. arXiv preprint (2014-12-19) [2022-12-27]. https://arxiv.org/abs/1412.6550
|
| [14] |
Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network [J/OL]. arXiv preprint (2014-12-19) [2022-12-27]. https://arxiv.org/abs/1503.02531
|
| [15] |
Ahn S, Hu S X, Damianou A, et al. Variational information distillation for knowledge transfer // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, 2019: 9163
|
| [16] |
Bridle J S. Training stochastic model recognition algorithms as networks can lead to maximum mutual information estimation of parameters // Advances in Neural Information Processing Systems. Denver, 1989: 211
|
| [17] |
Zoph B, Le Q V. Neural architecture search with reinforcement learning [J/OL]. arXiv preprint (2016-11-05) [2022-12-27]. https://arxiv.org/abs/1611.01578
|
| [18] |
Yu H B, Han Q, Li J B, et al. Search what you want: Barrier panelty NAS for mixed precision quantization // Proceedings of the European Conference on Computer Vision. Glasgow, 2020: 1
|
| [19] |
Prabhu A, Farhadi A, Rastegari M. Butterfly transform: An efficient FFT based neural architecture design // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle, 2020: 12021
|
| [20] |
Jaderberg M, Vedaldi A, Zisserman A. Speeding up convolutional neural networks with low rank expansions // 25th British Machine Vision Conference. Nottingham, 2014
|
| [21] |
Kim Y D, Park E, Yoo S, et al. Compression of deep convolutional neural networks for fast and low power mobile applications [J/OL]. arXiv preprint (2015-11-20) [2022-12-27]. https://arxiv.org/abs/1511.06530
|
| [22] |
Gusak J, Kholyavchenko M, Ponomarev E, et al. Automated multi-stage compression of neural networks // Proceedings of the IEEE International Conference on Computer Vision. Seoul, 2020: 2501
|
| [23] |
Lebedev V, Ganin Y, Rakhuba M, et al. Speeding-up convolutional neural networks using fine-tuned cp-decomposition [J/OL]. arXiv preprint (2014-12-19) [2022-12-27]. https://arxiv.org/abs/1412.6553
|
| [24] |
Phan A H, Sobolev K, Sozykin K, et al. Stable low-rank tensor decomposition for compression of convolutional neural network // 16th European Conference Computer Vision. Glasgow, 2020: 522
|
| [25] |
Deng C H, Sun F X, Qian X H, et al. Tie: energy-efficient tensor train-based inference engine for deep neural network. // Proceedings of the 46th International Symposium on Computer Architecture. Phoenix, 2020: 264
|
| [26] |
Huang H T, Ni L B, Yu H. LTNN: An energy efficient machine learning accelerator on 3D CMOS-RRAM for layer-wise tensorized neural network // 30th IEEE International System-on-Chip Conference. Munich, 2017: 280
|
| [27] |
Cheng Y, Li G Y, Wong N, et al. Deepeye: A deeply tensor-compressed neural network hardware accelerator // Proceedings of the International Conference on Computer-Aided Design. Westminster, 2019: 1
|
| [28] |
Kao C C, Hsieh Y Y, Chen C H, et al. Hardware acceleration in large-scale tensor decomposition for neural network compression // 65th IEEE International Midwest Symposium on Circuits and Systems. Fukuoka, 2022: 1
|
| [29] |
Krishnamoorthi R. Quantizing deep convolutional networks for efficient inference: A whitepaper [J/OL]. arXiv preprint (2018-06-21) [2022-12-27]. https://arxiv.org/abs/1806.08342
|
| [30] |
Nagel M, Fournarakis M, Amjad R A, et al. A white paper on neural network quantization [J/OL]. arXiv preprint (2021-06-15) [2022-12-27]. https://arxiv.org/abs/2106.08295
|
| [31] |
Jacob B, Kligys S, Chen B, et al. Quantization and training of neural networks for efficient integer-arithmetic-only inference // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, 2018: 2704
|
| [32] |
Reed J K, Devito Z, He H, et al. Torch. fx: Practical program capture and transformation for deep learning in Python [J/OL]. arXiv preprint (2021-12-15) [2022-12-27]. https://arxiv.org/abs/2112.08429
|
| [33] |
Siddegowda S, Fournarakis M, Nagel M, et al. Neural network quantization with AI model efficiency toolkit (AIMET) [J/OL]. arXiv preprint (2022-1-20) [2022-12-27]. https://arxiv.org/abs/2201.08442
|
| [34] |
Han S, Mao H Z, Dally W J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding [J/OL]. arXiv preprint (2022-01-20) [2022-12-27]. https://arxiv.org/abs/1510.00149
|
| [35] |
Miyashita D, Lee E H, Murmann B. Convolutional neural networks using logarithmic data representation [J/OL]. arXiv preprint (2016-3-3) [2022-12-27]. https://arxiv.org/abs/1603.01025
|
| [36] |
Zhou A J, Yao A B, Guo Y W, et al. Incremental network quantization: Towards lossless CNNs with low-precision weights [J/OL]. arXiv preprint (2017-02-10) [2022-12-27]. https://arxiv.org/abs/1702.03044
|
| [37] |
Li Y H, Dong X, Wang W. Additive Powers-of-two quantization: An efficient non-uniform discretization for neural networks [J/OL]. arXiv preprint (2019-09-28) [2022-12-27]. https://arxiv.org/abs/1909.13144
|
| [38] |
Liu X C, Ye M, Zhou D Y, et al. Post-training quantization with multiple points: Mixed precision without mixed precision // Proceedings of the AAAI Conference on Artificial Intelligence. Virtual Event, 2021: 8697
|
| [39] |
Xu C, Yao J Q, Lin Z C, et al. Alternating multi-bit quantization for recurrent neural networks [J/OL]. arXiv preprint (2018-02-01) [2022-12-27]. https://arxiv.org/abs/1802.00150
|
| [40] |
Zhang D Q, Yang J L, Ye D, et al. LQ-nets: Learned quantization for highly accurate and compact deep neural networks // Proceedings of the European Conference on Computer Vision. Munich, 2018: 373
|
| [41] |
Jung S, Son C, Lee S, et al. Learning to quantize deep networks by optimizing quantization intervals with task loss // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, 2019: 4345
|
| [42] |
Yamamoto K. Learnable companding quantization for accurate low-bit neural networks // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Nashville, 2021: 5027
|
| [43] |
Zhang Z Y, Shao W Q, Gu J W, et al. Differentiable dynamic quantization with mixed precision and adaptive resolution // International Conference on Machine Learning. Vienna, 2021: 12546
|
| [44] |
Liu Z C, Cheng K T, Huang D, et al. Nonuniform-to-uniform quantization: Towards accurate quantization via generalized straight-through estimation // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Baltimore, 2022: 4932
|
| [45] |
Choi J, Wang Z, Venkataramani S, et al. PACT: Parameterized clipping activation for quantized neural networks [J/OL]. arXiv preprint (2018-05-16) [2022-12-27]. https://arxiv.org/abs/1805.06085
|
| [46] |
Zhou S C, Wu Y X, Ni Z K, et al. Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients [J/OL]. arXiv preprint (2016-06-20) [2022-12-27]. https://arxiv.org/abs/1606.06160
|
| [47] |
Esser S K, McKinstry J L, Bablani D, et al. Learned step size quantization [J/OL]. arXiv preprint (2019-02-21) [2022-12-27]. https://arxiv.org/abs/1902.08153
|
| [48] |
Lee S, Kim H. Feature map-aware activation quantization for low-bit neural networks // 36th International Technical Conference on Circuits/Systems, Computers and Communications. Jeju, 2021: 1
|
| [49] |
Bengio Y, Léonard N, Courville A. Estimating or propagating gradients through stochastic neurons for conditional computation [J/OL]. arXiv preprint (2019-2-21) [2022-12-27]. https://arxiv.org/abs/1308.3432
|
| [50] |
Bhalgat Y, Lee J, Nagel M, et al. LSQ+: Improving low-bit quantization through learnable offsets and better initialization // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. Seattle, 2020: 2978
|
| [51] |
Liu Z G, Mattina M. Learning low-precision neural networks without straight-through estimator (STE) // Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence. Macao, 2019: 3066
|
| [52] |
Yang J W, Shen X, Xing J, et al. Quantization networks // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, 2019: 7300
|
| [53] |
Yang Z H, Wang Y H, Han K, et al. Searching for low-bit weights in quantized neural networks // Advances in Neural Information Processing Systems. Vancouver, 2020: 4091
|
| [54] |
Gong R H, Liu X L, Jiang S H, et al. Differentiable soft quantization: Bridging full-precision and low-bit neural networks // Proceedings of the IEEE International Conference on Computer Vision. Seoul, 2019: 4851
|
| [55] |
Kim D, Lee J, Ham B. Distance-aware quantization // Proceedings of the IEEE International Conference on Computer Vision. Montreal, 2022: 5251
|
| [56] |
Lee J, Kim D, Ham B. Network quantization with element-wise gradient scaling // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Virtual Event, 2021: 6448
|
| [57] |
Hubara I, Nahshan Y, Hanani Y, et al. Improving post training neural quantization: Layer-wise calibration and integer programming [J/OL]. arXiv preprint (2020-6-14) [2022-12-27]. https://arxiv.org/abs/2006.10518
|
| [58] |
Choukroun Y, Kravchik E, Yang F, et al. Low-bit quantization of neural networks for efficient inference // Proceedings of the IEEE International Conference on Computer Vision Workshops. Seoul, 2019: 3009
|
| [59] |
Fang J, Shafiee A, Abdel-Aziz H, et al. Post-training piecewise linear quantization for deep neural networks // Proceedings of the European Conference on Computer Vision. Glasgow, 2020: 69
|
| [60] |
Kullback S, Leibler R A. On information and sufficiency. Ann Math Stat, 1951, 22(1): 79 doi: 10.1214/aoms/1177729694
|
| [61] |
Nagel M, Baalen M, Blankevoort T, et al. Data-free quantization through weight equalization and bias correction // Proceedings of the IEEE International Conference on Computer Vision. Seoul, 2020: 1325
|
| [62] |
Hubara I, Nahshan Y, Hanani Y, et al. Accurate post training quantization with small calibration sets // International Conference on Machine Learning. Vienna, 2021: 4466
|
| [63] |
He X Y, Cheng J. Learning compression from limited unlabeled data // Proceedings of the European Conference on Computer Vision. Munich, 2018: 778
|
| [64] |
Sakr C, Dai S, Venkatesan R, et al. Optimal clipping and magnitude-aware differentiation for improved quantization-aware training // International Conference on Machine Learning. Baltimore, 2022: 19123
|
| [65] |
Nagel M, Amjad R A, Van Baalen M, et al. Up or down? adaptive rounding for post-training quantization // International Conference on Machine Learning. Virtual Event, 2020: 7197
|
| [66] |
Wang P S, Chen Q, He X Y, et al. Towards accurate post-training network quantization via bit-split and stitching // International Conference on Machine Learning. Virtual Event, 2020: 9847
|
| [67] |
Wang P S, Hu Q H, Zhang Y F, et al. Two-step quantization for low-bit neural networks // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, 2018: 4376
|
| [68] |
Diao H B, Li G Y, Xu S Y, et al. Attention round for post-training quantization [J/OL]. arXiv preprint (2022-07-07) [2022-12-27]. https://arxiv.org/abs/2207.03088
|
| [69] |
Li Y H, Gong R H, Tan X, et al. BRECQ: Pushing the limit of post-training quantization by block reconstruction [J/OL]. arXiv preprint (2021-02-10) [2022-12-27]. https://arxiv.org/abs/2102.05426
|
| [70] |
Wei X Y, Gong R H, Li Y H, et al. QDrop: Randomly dropping quantization for extremely low-bit post-training quantization [J/OL]. arXiv preprint (2022-03-11) [2022-12-27]. https://arxiv.org/abs/2203.05740
|
| [71] |
Yao H, Li P, Cao J, et al. Rapq: Rescuing accuracy for power-of-two low-bit post-training quantization [J/OL]. arXiv preprint (2022-04-26) [2022-12-27]. https://arxiv.org/abs/2204.12322
|
| [72] |
Jeon Y, Lee C, Cho E, et al. Mr. BiQ: Post-training non-uniform quantization based on minimizing the reconstruction error // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Baltimore, 2022: 12319
|
| [73] |
Li Z Y, Guo C, Zhu Z D, et al. Efficient activation quantization via adaptive rounding border for post-training quantization [J/OL]. arXiv preprint (2022-08-25) [2022-12-27]. https://arxiv.org/abs/2208.11945
|
| [74] |
Banner R, Nahshan Y, Hoffer E, et al. Post-training 4-bit quantization of convolution networks for rapid-deployment [J/OL]. arXiv preprint (2022-10-2) [2022-12-27]. https://arxiv.org/abs/1810.05723
|
| [75] |
Zhao R, Hu Y W, Dotzel J, et al. Improving neural network quantization without retraining using outlier channel splitting // International Conference on Machine Learning. Long Beach, 2019: 7543
|
| [76] |
Chikin V, Antiukh M. Data-free network compression via parametric non-uniform mixed precision quantization // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Baltimore, 2022: 450
|
| [77] |
Guo C, Qiu Y X, Leng J W, et al. SQuant: On-the-fly data-free quantization via diagonal hessian approximation [J/OL]. arXiv preprint (2022-02-14) [2022-12-27]. https://arxiv.org/abs/2202.07471
|
| [78] |
Yvinec E, Dapogny A, Cord M, et al. SPIQ: Data-free per-channel static input quantization [J/OL]. arXiv preprint (2022-03-28) [2022-12-27]. https://arxiv.org/abs/2203.14642
|
| [79] |
Yvinec E, Dapgony A, Cord M, et al. REx: Data-free residual quantization error expansion [J/OL]. arXiv preprint (2022-03-28) [2022-12-27]. https://arxiv.org/abs/2203.14645
|
| [80] |
Yu H C, Yang L J, Shi H. Is In-domain data really needed? A pilot study on cross-domain calibration for network quantization // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Nashville, 2021: 3037
|
| [81] |
Yao Z W, Aminabadi R Y, Zhang M J, et al. ZeroQuant: Efficient and affordable post-training quantization for large-scale transformers [J/OL]. arXiv preprint (2022-06-4) [2022-12-27]. https://arxiv.org/abs/2206.01861
|
| [82] |
Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets // Advances in Neural Information Processing Systems. Montreal, 2014: 2672
|
| [83] |
Cai Y H, Yao Z W, Dong Z, et al. ZeroQ: A novel zero shot quantization framework // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle, 2020: 13166
|
| [84] |
Haroush M, Hubara I, Hoffer E, et al. The knowledge within: Methods for data-free model compression // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle, 2020: 8491
|
| [85] |
Zhang X G, Qin H T, Ding Y F, et al. Diversifying sample generation for accurate data-free quantization // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Nashville, 2021: 15653
|
| [86] |
Li Y H, Zhu F, Gong R H, et al. MixMix: All You need for data-free compression are feature and data mixing // 2021 Proceedings of the IEEE International Conference on Computer Vision. Montreal, 2022: 4390
|
| [87] |
He X Y, Lu J H, Xu W X, et al. Generative zero-shot network quantization // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Nashville, 2021: 2994
|
| [88] |
Horton M, Jin Y Z, Farhadi A, et al. Layer-wise data-free CNN compression [J/OL]. arXiv preprint (2020-11-18) [2022-12-27]. https://arxiv.org/abs/2011.09058
|
| [89] |
Li Z K, Ma L P, Chen M J, et al. Patch similarity aware data-free quantization for vision transformers // Proceedings of the European Conference on Computer Vision. Tel Aviv, 2022: 154
|
| [90] |
Li Z K, Chen M J, Xiao J R, et al. PSAQ-ViT V2: Towards accurate and general data-free quantization for vision transformers[J/OL]. arXiv preprint (2022-09-13) [2022-12-27]. https://arxiv.org/abs/2209.05687
|
| [91] |
Xu S K, Li H K, Zhuang B H, et al. Generative Low-bitwidth Data Free Quantization // Proceedings of the European Conference on Computer Vision. Glasgow, 2020: 1
|
| [92] |
Choi Y, Choi J, El-Khamy M, et al. Data-free network quantization with adversarial knowledge distillation // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. Seattle, 2020: 3047
|
| [93] |
Li B W, Huang K, Chen S A, et al. DFQF: Data free quantization-aware fine-tuning // Asian Conference on Machine Learning. Bangkok, 2020: 289
|
| [94] |
Liu Y A, Zhang W, Wang J. Zero-shot adversarial quantization // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Nashville, 2021: 1512
|
| [95] |
Choi K, Hong D, Park N, et al. Qimera: Data-free quantization with synthetic boundary supporting samples // Advances in Neural Information Processing Systems. Virtual Event, 2021: 14835
|
| [96] |
Zhong Y S, Lin M B, Nan G R, et al. IntraQ: Learning synthetic images with intra-class heterogeneity for zero-shot network quantization // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Baltimore, 2022: 12329
|
| [97] |
Gao Y C, Zhang Z, Hong R C, et al. Towards feature distribution alignment and diversity enhancement for data-free quantization [J/OL]. arXiv preprint (2020-11-18) [2022-12-27]. https://arxiv.org/abs/2205.00179
|
| [98] |
Choi K, Lee H Y, Hong D, et al. It's all in the teacher: Zero-shot quantization brought closer to the teacher // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Baltimore, 2022: 8301
|
| [99] |
Wu B C, Wang Y H, Zhang P Z, et al. Mixed precision quantization of convnets via differentiable neural architecture search [J/OL]. arXiv preprint (2018-11-30) [2022-12-27]. https://arxiv.org/abs/1812.00090
|
| [100] |
Khoram S, Li J. Adaptive quantization of neural networks // 6th International Conference on Learning Representations. Vancouver, 2018: 1
|
| [101] |
Dong Z, Yao Z W, Gholami A, et al. HAWQ: Hessian aware quantization of neural networks with mixed-precision // 2019 Proceedings of the IEEE International Conference on Computer Vision. Seoul, 2020: 293
|
| [102] |
Dong Z, Yao Z W, Arfeen D, et al. HAWQ-v2: Hessian aware trace-weighted quantization of neural networks. Advances in Neural Information Processing Systems. 2020, 33: 18518
|
| [103] |
Wang K, Liu Z J, Lin Y J, et al. HAQ: Hardware-aware automated quantization with mixed precision // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, 2019: 8604
|
| [104] |
Yao Z, Dong Z, Zheng Z, et al. HAWQ-v3: Dyadic neural network quantization // International Conference on Machine Learning. Vienna, 2021: 11875
|
| [105] |
Li Z F, Ni B B, Zhang W, et al. Performance guaranteed network acceleration via high-order residual quantization // Proceedings of the IEEE International Conference on Computer Vision. Venice, 2017: 2603
|
| [106] |
Li Y, Ding W R, Liu C L, et al. TRQ: Ternary neural networks with residual quantization // Proceedings of the AAAI Conference on Artificial Intelligence. Virtual Event, 2021: 8538
|
| [107] |
Li Z F, Ni B B, Yang X K, et al. Residual quantization for low bit-width neural networks. IEEE Trans Multimed, 2023, 25: 214 doi: 10.1109/TMM.2021.3124095
|
| [108] |
Naumov M, Diril U, Park J, et al. On periodic functions as regularizers for quantization of neural networks [J/OL]. arXiv preprint (2018-11-24) [2022-12-27]. https://arxiv.org/abs/1811.09862
|
| [109] |
Zhou Y R, Moosavi-Dezfooli S M, Cheung N M, et al. Adaptive quantization for deep neural network // Proceedings of the AAAI Conference on Artificial Intelligence. New Orleans, 2018: 4596
|
| [110] |
Wang T Z, Wang K, Cai H, et al. APQ: Joint search for network architecture, pruning and quantization policy // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle, 2020: 2075
|
| [111] |
Courbariaux M, Bengio Y, David J P. BinaryConnect: Training deep neural networks with binary weights during propagations // Advances in Neural Information Processing Systems, 2015, 28: 3123
|
| [112] |
Courbariaux M, Hubara I, Soudry D, et al. Binarized neural networks: Training deep neural networks with weights and activations constrained to +1 or-1[J/OL]. arXiv preprint (2018-11-24) [2022-12-27]. https://arxiv.org/abs/1602.02830
|
| [113] |
Rastegari M, Ordonez V, Redmon J, et al. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks // Proceedings of the European Conference on Computer Vision. Amsterdam, 2016: 525
|
| [114] |
Lin Z H, Courbariaux M, Memisevic R, et al. Neural networks with few multiplications [J/OL]. arXiv preprint (2015-10-11) [2022-12-27]. https://arxiv.org/abs/1510.03009
|
| [115] |
Li F F, Liu B, Wang X X. Ternary weight networks [J/OL]. arXiv preprint (2016-05-16) [2022-12-27]. https://arxiv.org/abs/1605.04711
|
| [116] |
Wan D W, Shen F M, Liu L, et al. TBN: Convolutional neural network with ternary inputs and binary weights // Proceedings of the European Conference on Computer Vision. Munich, 2018: 322
|
| [117] |
Xu Z, Cheung R C C. Accurate and compact convolutional neural networks with trained binarization [J/OL]. arXiv preprint (2019-09-25) [2022-12-27]. https://arxiv.org/abs/1909.11366
|
| [118] |
Bulat A, Tzimiropoulos G. XNOR-net++: Improved binary neural networks [J/OL]. arXiv preprint (2019-09-30) [2022-12-27]. https://arxiv.org/abs/1909.13863
|
| [119] |
Hou L, Yao Q, Kwok J T. Loss-aware binarization of deep networks [J/OL]. arXiv preprint (2016-11-05) [2022-12-27]. https://arxiv.org/abs/1611.01600
|
| [120] |
Mishra A, Marr D. Apprentice: Using knowledge distillation techniques to improve low-precision network accuracy [J/OL]. arXiv preprint (2017-11-15) [2022-12-27]. https://arxiv.org/abs/1711.05852
|
| [121] |
Martinez B, Yang J, Bulat A, et al. Training binary neural networks with real-to-binary convolutions [J/OL]. arXiv preprint (2020-03-25) [2022-12-27]. https://arxiv.org/abs/2003.11535
|
| [122] |
Kingma D, Ba J. Adam: A Method for Stochastic Optimization [J/OL]. arXiv preprint (2014-12-22) [2022-12-27]. https://arxiv.org/abs/1412.6980
|
| [123] |
雷杰, 高鑫, 宋杰, 等. 深度網絡模型壓縮綜述. 軟件學報, 2018, 29(2):251 doi: 10.13328/j.cnki.jos.005428
Lei J, Gao X, Song J, et al. Survey of deep neural network model compression. J Softw, 2018, 29(2): 251 doi: 10.13328/j.cnki.jos.005428
|
| [124] |
李江昀, 趙義凱, 薛卓爾, 等. 深度神經網絡模型壓縮綜述. 工程科學學報, 2019, 41(10):1229
Li J Y, Zhao Y K, Xue Z E, et al. A survey of model compression for deep neural networks. Chin J Eng, 2019, 41(10): 1229
|
| [125] |
高晗, 田育龍, 許封元, 等. 深度學習模型壓縮與加速綜述. 軟件學報, 2021, 32(1):68 doi: 10.13328/j.cnki.jos.006096
Gao H, Tian Y L, Xu F Y, et al. Survey of deep learning model compression and acceleration. J Softw, 2021, 32(1): 68 doi: 10.13328/j.cnki.jos.006096
|
| [126] |
張弛, 田錦, 王永森, 等. 神經網絡模型壓縮方法綜述 // 中國計算機用戶協會網絡應用分會2018年第二十二屆網絡新技術與應用年會論文集. 蘇州, 2018: 7
Zhang C, Tian J, Wang Y S, et al. Review of neural network model compression methods // Proceedings of the 22nd Annual Conference on New Network Technology and Application of Network Application of China Computer Users Association in 2018. Suzhou, 2018: 7
|
| [127] |
紀榮嶸, 林紹輝, 晁飛, 等. 深度神經網絡壓縮與加速綜述. 計算機研究與發展, 2018, 55(9):1871 doi: 10.7544/issn1000-1239.2018.20180129
Ji R R, Lin S H, Chao F, et al. Deep neural network compression and acceleration: A review. J Comput Res Dev, 2018, 55(9): 1871 doi: 10.7544/issn1000-1239.2018.20180129
|
| [128] |
唐武海, 董博, 陳華, 等. 深度神經網絡模型壓縮方法綜述. 智能物聯技術, 2021, 4(6):1
Tang W H, Dong B, Chen H, et al. Survey of model compression methods for deep neural networks. Intelligent IoT AI, 2021, 4(6): 1
|
| [129] |
Sandler M, Howard A, Zhu M L, et al. MobileNetV2: Inverted residuals and linear bottlenecks // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, 2018: 4510
|
| [130] |
Howard A G, Zhu M L, Chen B, et al. MobileNets: Efficient convolutional neural networks for mobile vision applications [J/OL]. arXiv preprint (2017-4-17) [2022-12-27]. https://arxiv.org/abs/1704.04861
|
| [131] |
Bondarenko Y, Nagel M, Blankevoort T. Understanding and overcoming the challenges of efficient transformer quantization [J/OL]. arXiv preprint (2017-4-17) [2022-12-27]. https://arxiv.org/abs/2109.12948
|
| [132] |
He X, Zhao K Y, Chu X W. AutoML: A survey of the state-of-the-art. Knowl Based Syst, 2021, 212: 106622 doi: 10.1016/j.knosys.2020.106622
|

Figures(6)
Editorial Department of Journal of Engineering Sciences
Address:No. 30 College Road, Haidian District, BeijingPost Code:100083 Tel:(010)62333436
Supported by:
Beijing Renhe Information Technology Co. Ltd




 DownLoad:
DownLoad: