

-
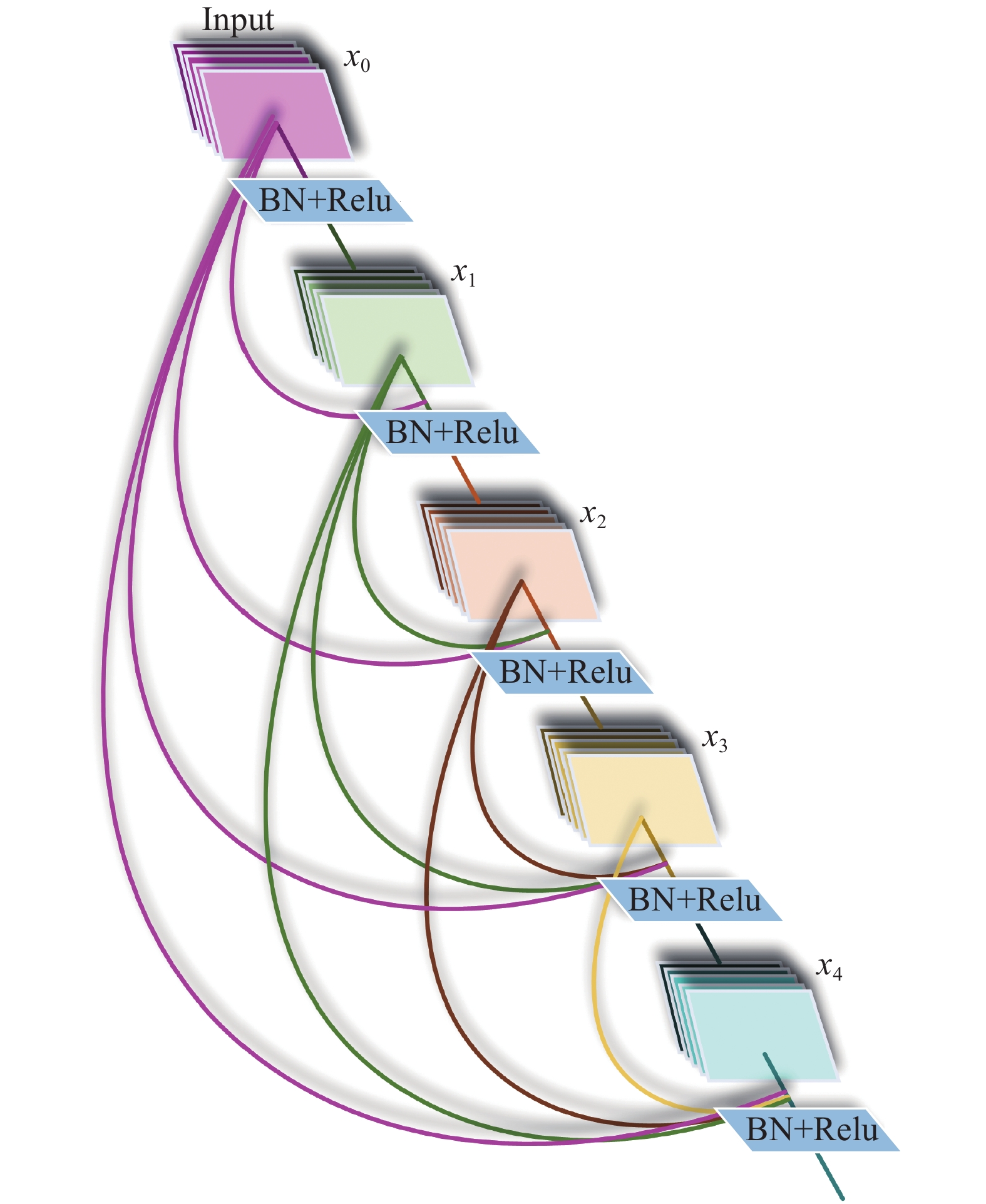
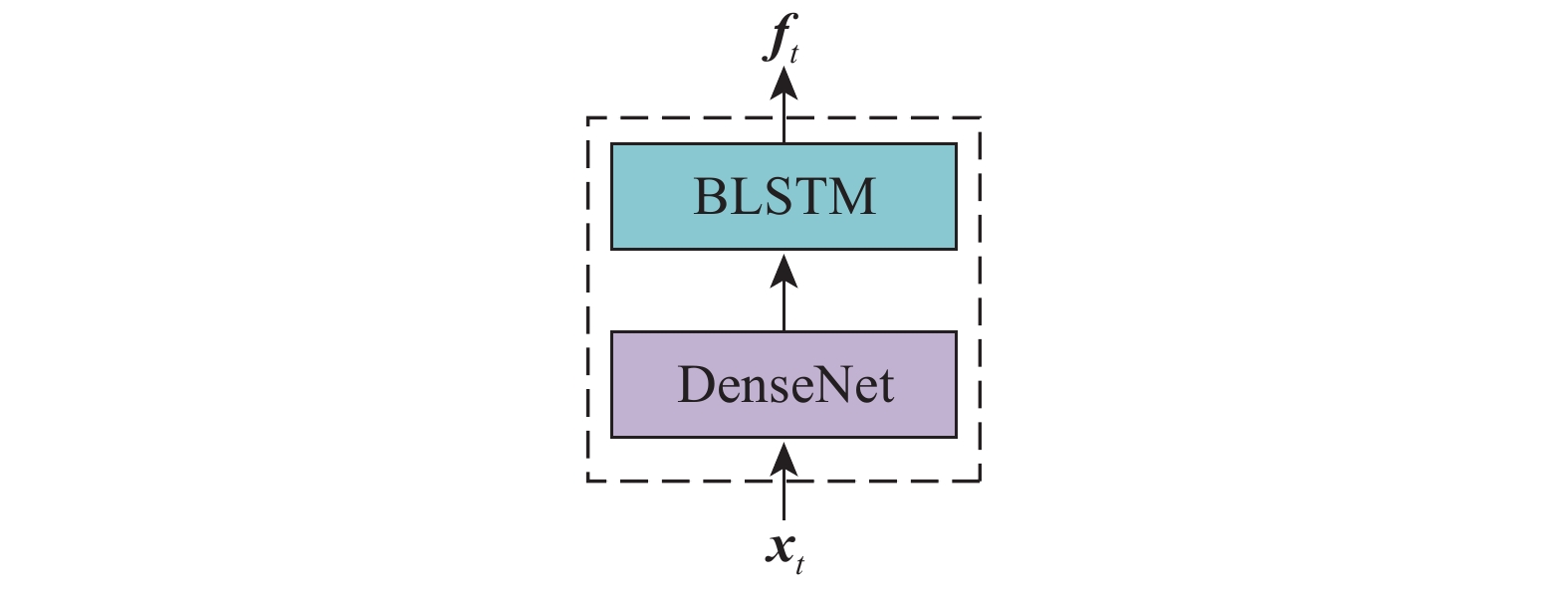
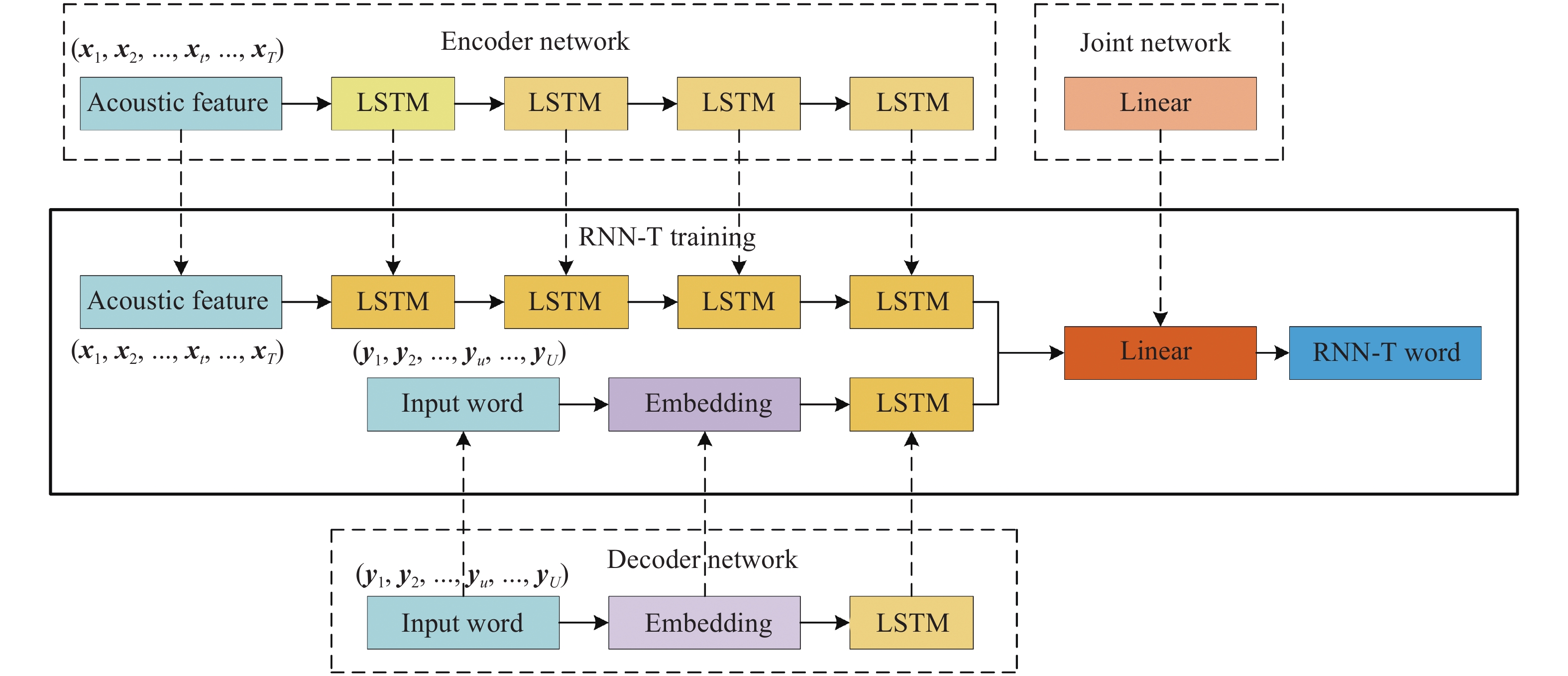
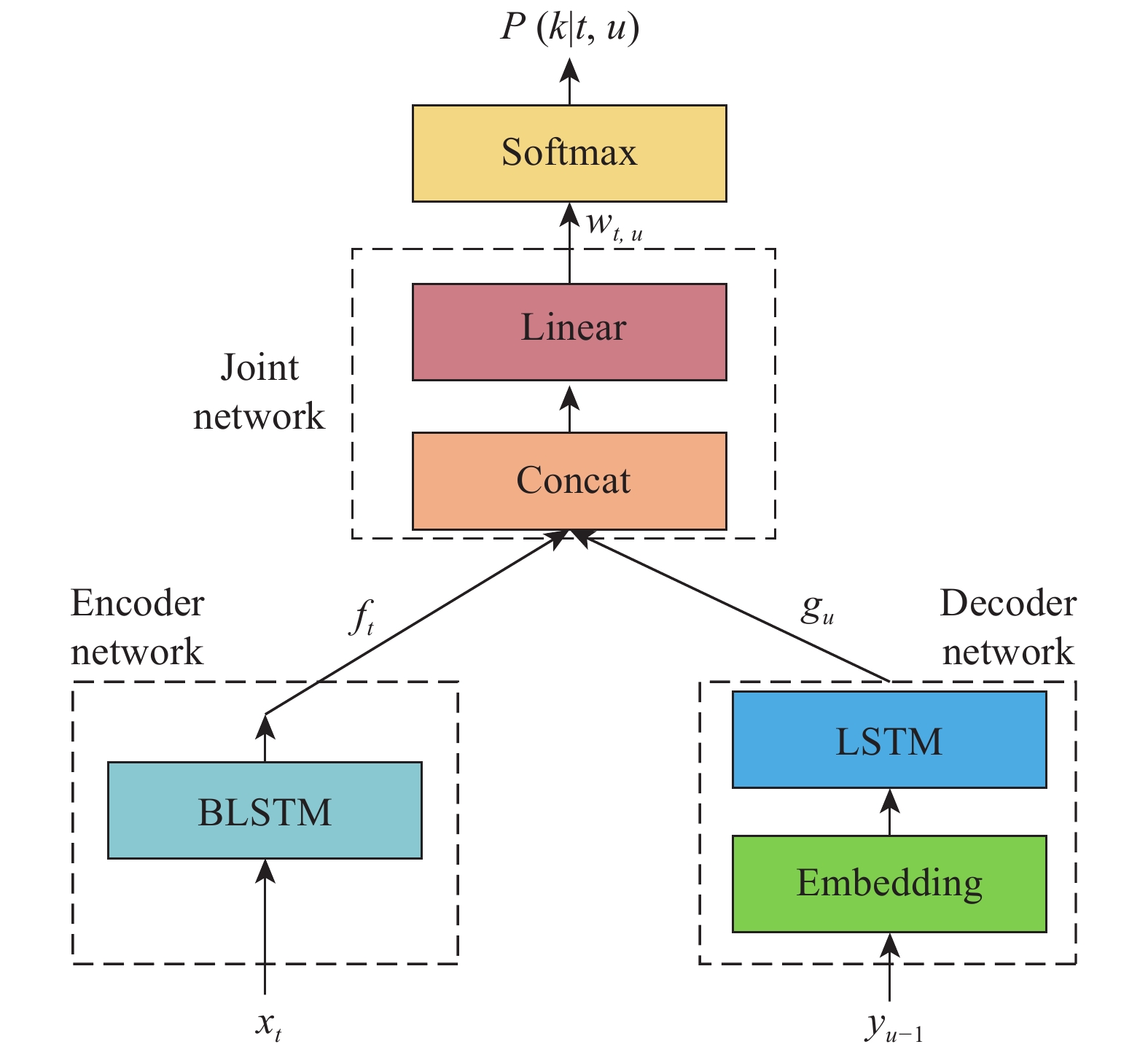
摘要: 為解決RNN–T語音識別時預測錯誤率高、收斂速度慢的問題,本文提出了一種基于DL–T的聲學建模方法。首先介紹了RNN–T聲學模型;其次結合DenseNet與LSTM網絡提出了一種新的聲學建模方法— —DL–T,該方法可提取原始語音的高維信息從而加強特征信息重用、減輕梯度問題便于深層信息傳遞,使其兼具預測錯誤率低及收斂速度快的優點;然后,為進一步提高聲學模型的準確率,提出了一種適合DL–T的遷移學習方法;最后為驗證上述方法,采用DL–T聲學模型,基于Aishell–1數據集開展了語音識別研究。研究結果表明:DL–T相較于RNN–T預測錯誤率相對降低了12.52%,模型最終錯誤率可達10.34%。因此,DL–T可顯著改善RNN–T的預測錯誤率和收斂速度。Abstract: Speech has been a natural and effective way of communication, widely used in the field of information-communication and human–machine interaction. In recent years, various algorithms have been used for achieving efficient communication. The main purpose of automatic speech recognition (ASR), one of the key technologies in this field, is to convert the analog signals of input speech into corresponding text digital signals. Further, ASR can be divided into two categories: one based on hidden Markov model (HMM) and the other based on end to end (E2E) models. Compared with the former, E2E models have a simple modeling process and an easy training model and thus, research is carried out in the direction of developing E2E models for effectively using in ASR. However, HMM-based speech recognition technologies have some disadvantages in terms of prediction error rate, generalization ability, and convergence speed. Therefore, recurrent neural network–transducer (RNN–T), a typical E2E acoustic model that can model the dependencies between the outputs and can be optimized jointly with a Language Model (LM), was proposed in this study. Further, a new acoustic model of DL–T based on DenseNet (dense convolutional network)–LSTM (long short-term memory)–Transducer, was proposed to solve the problems of a high prediction error rate and slow convergence speed in a RNN–T. First, a RNN–T was briefly introduced. Then, combining the merits of both DenseNet and LSTM, a novel acoustic model of DL–T, was proposed in this study. A DL–T can extract high-dimensional speech features and alleviate gradient problems and it has the advantages of low character error rate (CER) and fast convergence speed. Apart from that, a transfer learning method suitable for a DL–T was also proposed. Finally, a DL–T was researched in speech recognition based on the Aishell–1 dataset for validating the abovementioned methods. The experimental results show that the relative CER of DL–T is reduced by 12.52% compared with RNN–T, and the final CER is 10.34%, which also demonstrates a low CER and better convergence speed of the DL–T.
-
Key words:
- deep learning /
- speech recognition /
- acoustic model /
- DL–T /
- transfer learning
-
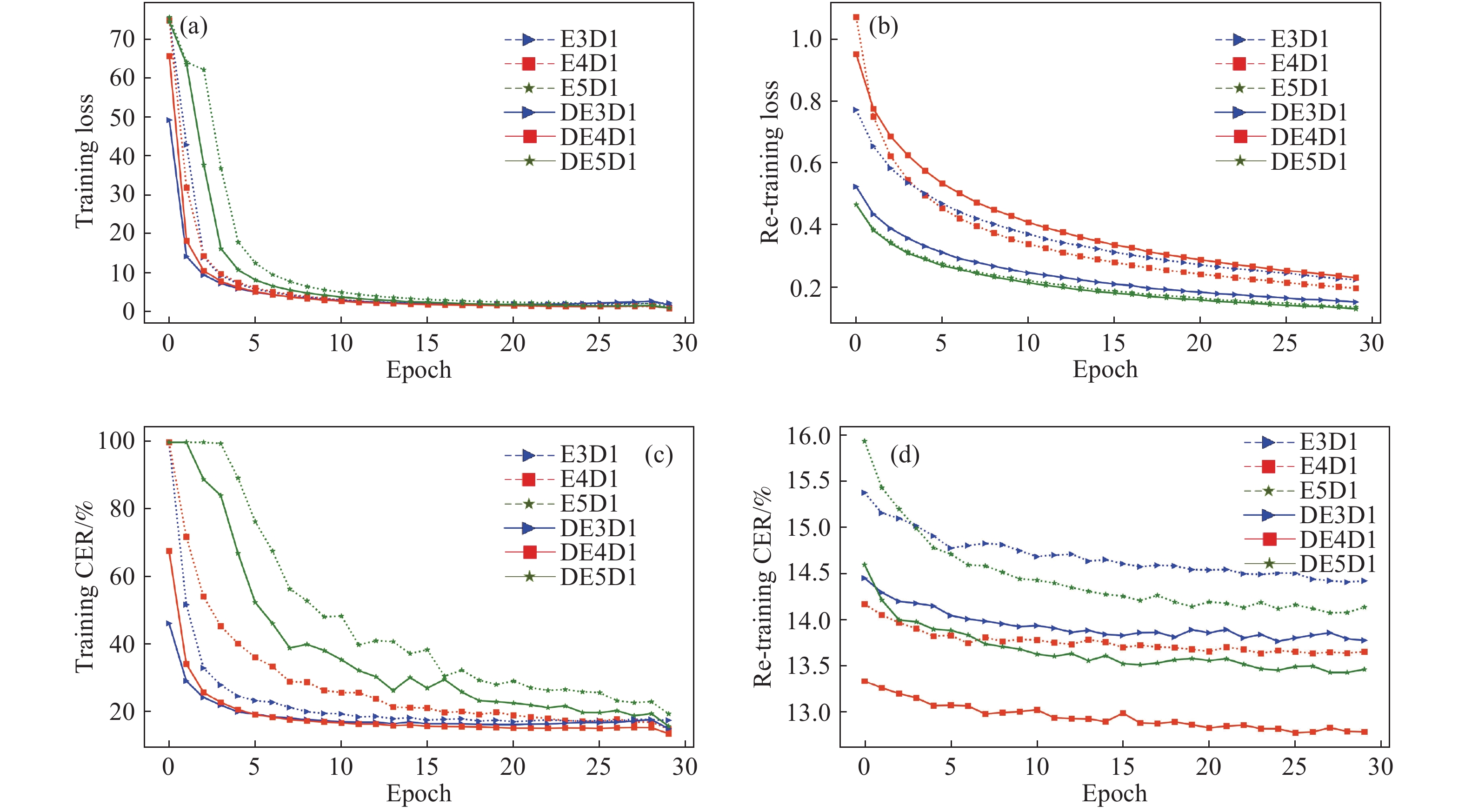
圖 5 基線模型實驗曲線圖。(a)初始訓練損失值曲線圖;(b)遷移學習損失值曲線圖;(c)初始訓練錯誤率曲線圖;(d)遷移學習錯誤率曲線圖
Figure 5. Curves of the baseline model:(a) loss curve on initial training stage; (b) loss curve on transfer learning stage; (c) prediction error rate curve on initial training stage; (d) prediction error rate curve on transfer learning stage
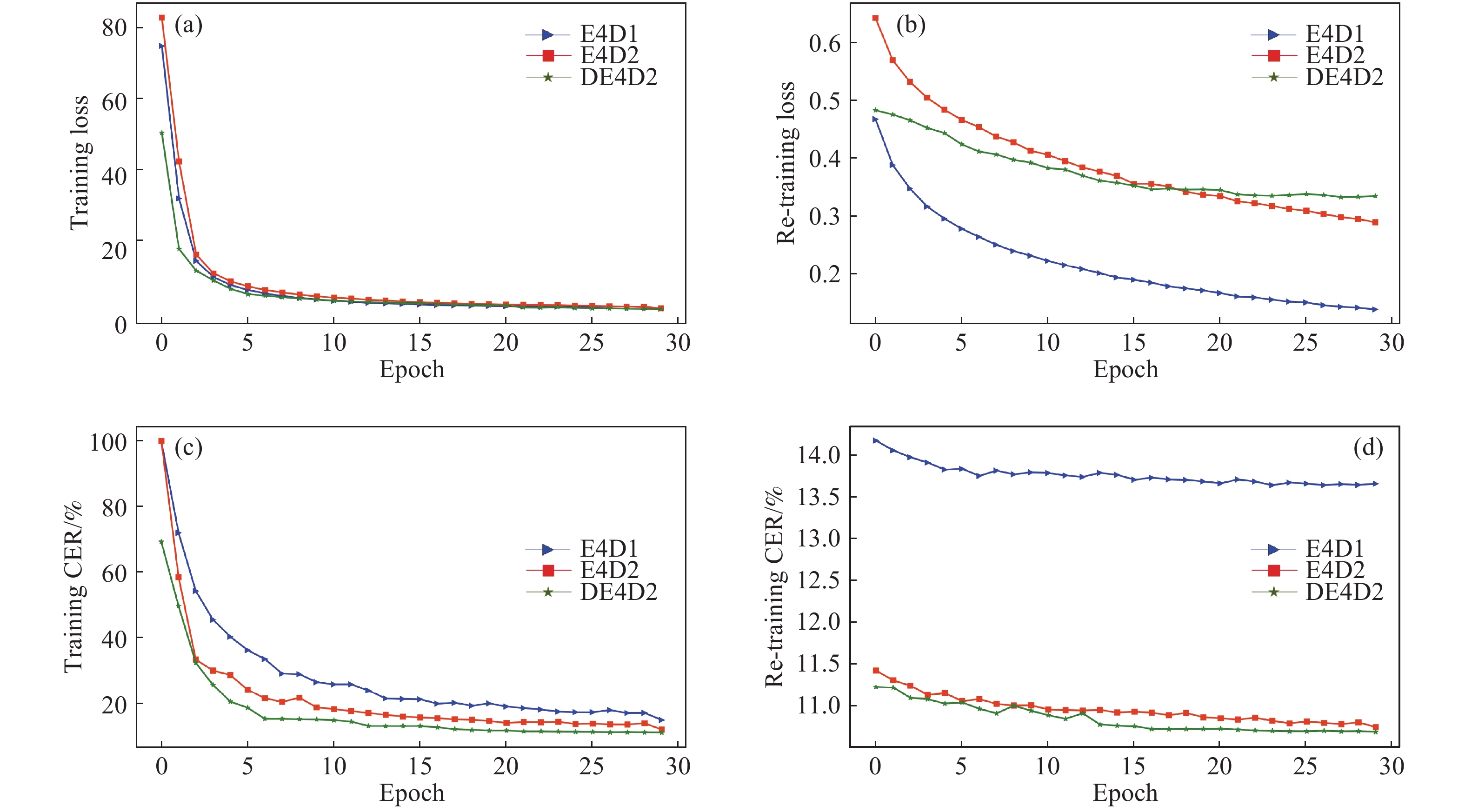
圖 6 DL–T實驗曲線圖。(a)不同聲學模型初始訓練損失值曲線圖;(b)不同聲學模型遷移學習損失值曲線圖;(c)不同聲學模型初始訓練錯誤率曲線圖;(d)不同聲學模型遷移學習錯誤率曲線圖
Figure 6. Curves of the DenseNet–LSTM–Transducer: (a) loss curve of different acoustic models on initial training stage; (b) loss curve of different acoustic models on transfer learning stage; (c) prediction error rate curve of different acoustic models on initial training stage; (d) prediction error rate curve of different acoustic models on transfer learning stage
表 1 RNN–T基線模型實驗結果
Table 1. Experimental results of RNN–T’s baseline
% Acoustic model Initial model TL TL+LM Dev CER Test CER Dev CER Test CER Dev CER Test CER RNN-T[15] 10.13 11.82 E3D1 17.69 18.92 14.42 16.31 12.07 13.57 E4D1 15.03 17.39 13.66 15.58 11.25 13.07 E5D1 19.62 22.35 14.14 16.22 11.89 13.53 E4D2 12.12 14.54 10.74 12.74 9.13 10.65  下載: 導出CSV
下載: 導出CSV
表 3 不同語言模型對聲學模型的影響
Table 3. Effects of different language model weights on the acoustic model
% Value of LM Dev CER Test CER 0.2 8.91 10.47 0.3 8.80 10.34 0.4 8.89 10.45
下載: 導出CSV
259luxu-164<th id="5nh9l"></th> <strike id="5nh9l"></strike> <th id="5nh9l"><noframes id="5nh9l"><th id="5nh9l"></th> <strike id="5nh9l"></strike> <th id="5nh9l"><noframes id="5nh9l"> <th id="5nh9l"></th> <strike id="5nh9l"><noframes id="5nh9l"><span id="5nh9l"></span> <span id="5nh9l"><noframes id="5nh9l"><span id="5nh9l"></span> <strike id="5nh9l"><noframes id="5nh9l"><strike id="5nh9l"></strike> <span id="5nh9l"><noframes id="5nh9l"> <span id="5nh9l"><noframes id="5nh9l"> <span id="5nh9l"></span> <span id="5nh9l"><video id="5nh9l"></video></span> <th id="5nh9l"><noframes id="5nh9l"><th id="5nh9l"></th> -
參考文獻
[1] Hinton G, Deng L, Yu D, et al. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups. IEEE Signal Process Mag, 2012, 29(6): 82 [2] Graves A, Mohamed A, Hinton G E. Speech recognition with deep recurrent neural networks // 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. Vancouver, 2013: 6645 [3] Seltzer M L, Ju Y C, Tashev I, et al. In-car media search. IEEE Signal Process Mag, 2011, 28(4): 50 [4] Yu D, Deng L. Analytical Deep Learning: Speech Recognition Practice. Yu K, Qian Y M, Translated. 5th ed. Beijing: Publishing House of Electronic Industry, 2016俞棟, 鄧力. 解析深度學習: 語音識別實踐. 俞凱, 錢彥旻, 譯. 5版. 北京: 電子工業出版社, 2016 [5] Peddinti V, Wang Y M, Povey D, et al. Low latency acoustic modeling using temporal convolution and LSTMs. IEEE Signal Process Lett, 2018, 25(3): 373 [6] Povey D, Cheng G F, Wang Y M, et al. Semi-orthogonal low-rank matrix factorization for deep neural networks // Conference of the International Speech Communication Association. Hyderabad, 2018: 3743 [7] Xing A H, Zhang P Y, Pan J L, et al. SVD-based DNN pruning and retraining. J Tsinghua Univ Sci Technol, 2016, 56(7): 772刑安昊, 張鵬遠, 潘接林, 等. 基于SVD的DNN裁剪方法和重訓練. 清華大學學報: 自然科學版, 2016, 56(7):772 [8] Graves A, Fernandez S, Gomez F, et al. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks // Proceedings of the 23rd International Conference on Machine Learning. Pittsburgh, 2006: 369 [9] Zhang Y, Pezeshki M, Brakel P, et al. Towards end-to-end speech recognition with deep convolutional neural networks // Conference of the International Speech Communication Association. California, 2016: 410 [10] Zhang W, Zhai M H, Huang Z L, et al. Towards end-to-end speech recognition with deep multipath convolutional neural networks // 12th International Conference on Intelligent Robotics and Applications. Shenyang, 2019: 332 [11] Zhang S L, Lei M. Acoustic modeling with DFSMN-CTC and joint CTC-CE learning // Conference of the International Speech Communication Association. Hyderabad, 2018: 771 [12] Dong L H, Xu S, Xu B. Speech-transformer: a no-recurrence sequence-to-sequence model for speech recognition // IEEE International Conference on Acoustics, Speech and Signal Processing. Calgary, 2018: 5884 [13] Graves A. Sequence transduction with recurrent neural networks // Proceedings of the 29th International Conference on Machine Learning. Edinburgh, 2012: 235 [14] Rao K, Sak H, Prabhavalkar R. Exploring architectures, data and units for streaming end-to-end speech recognition with RNN-transducer // 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). Okinawa, 2017 [15] Tian Z K, Yi J Y, Tao J H, et al. Self-attention transducers for end-to-end speech recognition // Conference of the International Speech Communication Association. Graz, 2019: 4395 [16] Bu H, Du J Y, Na X Y, et al. Aishell-1: an open-source mandarin speech corpus and a speech recognition baseline[J/OL]. arXiv preprint (2017-09-16)[2019-10-10]. http://arxiv.org/abs/17-09.05522 [17] Battenberg E, Chen J T, Child R, et al. Exploring neural transducers for end-to-end speech recognition // 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). Okinawa, 2017: 206 [18] Williams R J, Zipser D. Gradient-based learning algorithms for recurrent networks and their computational complexity // Back-propagation: Theory, Architectures and Applications. 1995: 433 [19] Huang G, Liu Z, Maaten L V D, et al. Densely connected convolutional networks // IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, 2017: 4700 [20] Cao Y, Huang Z L, Zhang W, et al. Urban sound event classification with the N-order dense convolutional network. J Xidian Univ Nat Sci, 2019, 46(6): 9曹毅, 黃子龍, 張威, 等. N-DenseNet的城市聲音事件分類模型. 西安電子科技大學學報: 自然科學版, 2019, 46(6):9 [21] Zhang S, Gong Y H, Wang J J. The development of deep convolutional neural networks and its application in computer vision. Chin J Comput, 2019, 42(3): 453張順, 龔怡宏, 王進軍. 深度卷積神經網絡的發展及其在計算機視覺領域的應用. 計算機學報, 2019, 42(3):453 [22] Zhou F Y, Jin L P, Dong J. Review of convolutional neural networks. Chin J Comput, 2017, 40(6): 1229 doi: 10.11897/SP.J.1016.2017.01229周飛燕, 金林鵬, 董軍. 卷積神經網絡研究綜述. 計算機學報, 2017, 40(6):1229 doi: 10.11897/SP.J.1016.2017.01229 [23] Yi J Y, Tao J H, Liu B, et al. Transfer learning for acoustic modeling of noise robust speech recognition. J Tsinghua Univ Sci Technol, 2018, 58(1): 55易江燕, 陶建華, 劉斌, 等. 基于遷移學習的噪聲魯棒性語音識別聲學建模. 清華大學學報: 自然科學版, 2018, 58(1):55 [24] Xue J B, Han J Q, Zheng T R, et al. A multi-task learning framework for overcoming the catastrophic forgetting in automatic speech recognition[J/OL]. arXiv preprint (2019-04-17)[2019-10-10]. https://arxiv.org/abs-/1904.08039 [25] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality // Proceedings of the 26th International Conference on Neural Information Processing Systems - Volume 2.Canada, 2013: 3111 [26] Povey D, Ghoshal A, Boulianne G, et al. The Kaldi speech recognition toolkit // IEEE 2011 Workshop on Automatic Speech Recognition and Understanding. Big Island, 2011 [27] Paszke A, Gross S, Chintala S, et al. Automatic differentiation in PyTorch // 31st Conference on Neural Information Processing Systems. Long Beach, 2017 [28] Shan C, Weng C, Wang G, et al. Component fusion: learning replaceable language model component for end-to-end speech recognition system // IEEE International Conference on Acoustics, Speech and Signal Processing. Brighton, 2019: 5361 -
 點擊查看大圖
點擊查看大圖
計量
- 文章訪問數: 2836
- HTML全文瀏覽量: 1245
- PDF下載量: 138
- 被引次數: 0
